Static Analysis: Detecting Branch Divergence in GPU Code
Introduction: The Cost of an If Statement
Here’s a thought experiment. You write a GPU kernel that processes 100 million elements in parallel. Inside the kernel, there’s a single if (threadIdx.x % 2 == 0) branch. Half the threads take one path, half take the other.
On a CPU with branch prediction and out-of-order execution, this cost is often mitigated (not eliminated). On a GPU, it can cut your throughput roughly in half.
The reason is SIMT execution: threads in the same warp execute in lockstep, sharing a single program counter. When threads disagree about which branch to take, the warp must execute both paths sequentially, masking off the threads that don’t participate in each one. The arithmetic units that should be doing useful work are instead sitting idle behind a mask.
Project 5 of Georgia Tech’s CS 8803: GPU Hardware and Software asks a deceptively difficult question: can we detect which branches will cause this problem at compile time, before the program ever runs?
The answer is a classic piece of compiler theory applied to GPU assembly code: build a control flow graph over the program’s basic blocks, run a def-use dataflow analysis to track which values derive from thread IDs, and flag any branch whose condition is thread-ID-dependent.
I keep this post focused on the core ideas behind Project 5. For the broader course overview, see: GPU Hardware and Software: A Retrospective.
Branch Divergence Explained
SIMT Execution and Active Masks
A GPU warp consists of 32 threads that execute in lockstep: every cycle, the warp fetches one instruction and all 32 threads execute it simultaneously on their own data. This is the Single Instruction Multiple Thread (SIMT) model.
When all threads in a warp follow the same control flow path, this works beautifully, with near-perfect utilization. The problem arises at branches.
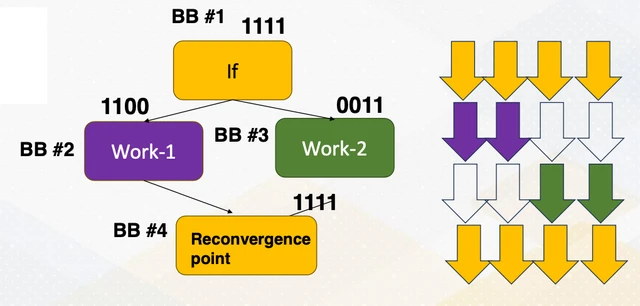
When threads in a warp take different branches, the hardware uses an active mask to track which threads should be executing at each instruction. The warp first executes one branch path with some threads masked off (inactive), then executes the other branch path with the opposite mask. The total work is the sum of both paths, so any throughput benefit of parallelism within a divergent branch is lost.

Predicated Execution: The Compiler’s First Response
For branches with very small bodies, compilers often eliminate the branch entirely using predication. Instead of branching, both sides of the if-else are converted to predicated instructions, i.e., instructions that execute conditionally based on a predicate register but are always fetched.
// Divergent branch version
BRA.U LABEL_ELSE;
// ... work 1 ...
BRA.U LABEL_END;
LABEL_ELSE:
// ... work 2 ...
LABEL_END:
// Predicated version, no branch instructions, no divergence
ISETP.LT.AND P0, PT, R0, c[0][0], PT; // set predicate P0 = (r0 < threshold)
@P0 FADD R1, R2, R3; // only executes if P0 is true
@!P0 FADD R1, R4, R5; // only executes if P0 is falseThe downside of predication: both sides’ instructions are always fetched and dispatched, even when masked. For large branch bodies this wastes more time than the divergence cost it avoids. So predication is only applied for small branches, while larger divergent branches remain as actual branches in the assembly.
The Reconvergence Problem
Managing divergent branches requires hardware support. When a warp hits a divergent branch, it needs to:
- Know where the two paths reconverge (so it knows when all threads can run together again)
- Store the “other” path’s PC address so it can come back and run those threads

The reconvergence point, called the immediate post-dominator in compiler terms, is the first basic block that all paths from a branch must eventually pass through. Identifying it is a compiler and control-flow-analysis job. In older SIMT-stack style explanations, explicit reconvergence structure is central. On Volta-and-later GPUs with independent thread scheduling, the mechanism is more flexible, but divergence analysis is still crucial for performance and code generation quality. So compile-time divergence detection matters primarily for optimization and predictability, not as a universal hardware-correctness requirement.
The Compiler’s View: SASS and CFGs
The GPU Compilation Pipeline
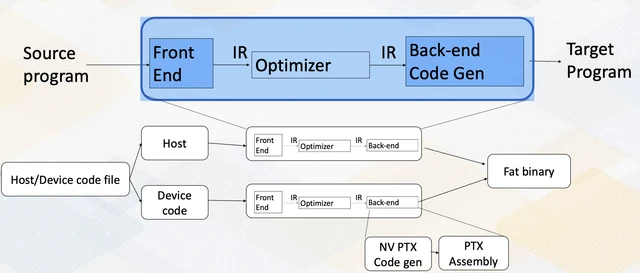
Understanding what Project 5 analyzes requires understanding where SASS lives in this stack. The project assumes the standard CUDA toolchain path. Clang/LLVM-based CUDA flows also exist, but they are an alternative frontend/backend path rather than the canonical NVIDIA pipeline.
PTX (Parallel Thread Execution) is NVIDIA’s virtual ISA: it’s architecture-independent, uses infinite virtual registers, and is the format that NVCC produces. SASS (Shader ASSembly) is the real machine-level assembly that runs on specific GPU hardware. It has physical register allocation, architecture-specific instruction encodings, and includes the predicates and branch targets that the actual GPU pipeline will execute.
Project 5 works at the SASS level, using a Georgia Tech-developed tool called the SASS Lifter that parses SASS into a form that Python can analyze. You’re analyzing the lowest level of the software stack, the actual instructions the GPU hardware will execute.
Basic Blocks
To analyze a program’s control flow, you first need to decompose it into basic blocks. A basic block is a maximal sequence of instructions with:
- Single entry: only the first instruction can be reached from outside the block (no jumps into the middle)
- Single exit: once you enter, you execute every instruction (no branches except at the very end)
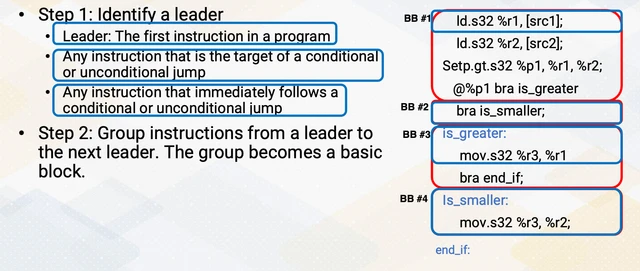
The algorithm to find basic blocks from a flat instruction list:
- Identify leaders: the first instruction, any instruction that is the target of a branch, and any instruction immediately following a branch
- Each basic block spans from one leader to just before the next leader
Control Flow Graphs
Once you have basic blocks, you can build a Control Flow Graph (CFG): a directed graph where nodes are basic blocks and edges are the possible control-flow transitions between them. An edge from block A to block B means “execution can flow from A to B,” either because A ends with an unconditional branch to B, or because A ends with a conditional branch that might go to B.

The CFG is the data structure that makes global analysis possible. Local analysis (within one basic block) is straightforward. Global analysis, reasoning about how values flow through the whole program including branches and loops, requires the CFG.
Dataflow Analysis for Divergence Detection
Before we jump into equations, here’s the minimum compiler background you need for this section. You do not need full SSA construction details or optimization-pass internals to follow the project. The only pieces that matter are: basic blocks, CFG edges, and def-use relationships between instructions. Once those are in place, the divergence detector is just an iterative propagation problem over a finite graph. If you’ve seen liveness/reaching-definitions once, this will feel familiar.
At a high level, this part of the pipeline follows a classical compiler dataflow pipeline: normalize control flow into basic blocks/CFG, reason about value versions (SSA intuition), run reaching-definitions style propagation to build def-use links, then propagate thread-ID taint to identify divergent branches. The project implementation operates on SASS and reused register names, but the analysis shape is the same classical compiler pipeline.
The Core Idea
Branch divergence in GPU code has a precise characterization: a branch is divergent if its condition depends, directly or transitively, on a thread ID.
Thread IDs enter the program through special-purpose registers loaded by S2R (Special Register Read) instructions:
S2R R0, SR_TID.X; // load threadIdx.x into R0
S2R R1, SR_TID.Y; // load threadIdx.y into R1Any instruction that uses R0 or R1 is now thread-ID-dependent. Any instruction that uses those results is also thread-ID-dependent. This taint propagation flows forward through the program via def-use chains until it either reaches a branch (potential divergence) or a dead end.
Reaching Definitions
The foundational dataflow analysis for this purpose is reaching definitions: for each use of a register at a program point, which prior definitions of that register might have produced the value?

The reaching definitions equations:
OUT[B] = GEN[B] ∪ (IN[B] - KILL[B])
IN[B] = ∪ OUT[P] for all predecessors P of BThis is computed iteratively until convergence: start with all sets empty, apply the equations repeatedly until no set changes. The result, for each program point, tells you the set of definitions that could have produced each register’s value.
Building the Def-Use Table
Project 5’s first task is constructing a def-use table: a mapping from each register definition to the set of uses that read from it, traversed across the full CFG.
The traversal visits each basic block in CFG order (using predecessor/successor relationships), tracking the “latest” definition of each register seen so far. When an instruction uses a register, you record a def-use pair: the current live definition of that register → this instruction.
One subtlety matters here: the same register name can have multiple definitions at different points in the CFG (not SSA form, register names are reused). You need to track which definition is “live” at each point, which is exactly what reaching definitions computes.
Taint Propagation from Thread IDs
With the def-use table in hand, task 2 is identifying which instructions are “tainted,” i.e., thread-ID-dependent.
The procedure:
- Find all
S2Rinstructions that load thread ID registers. These are the taint sources. - Using the def-use table, find all instructions that use the values defined by
S2R. Mark them tainted. - Repeat: find all instructions that use the values defined by tainted instructions. Mark them tainted too.
- Continue until no new instructions are added to the tainted set.
This is a forward dataflow propagation: taint flows in the direction of data flow (from definitions to uses). The fixed-point termination is guaranteed because the set of instructions is finite and the tainted set only grows.
Identifying Divergent Branches
Task 3 is the payoff: from the tainted instruction set, find all branch instructions. A tainted branch instruction is a potential divergence point, because its condition depends on thread ID, so different threads in the same warp may evaluate it differently.
# Conceptual, illustrates the detection logic, not the project code
for instr in tainted_instructions:
if is_branch(instr):
branch_divergence_inst_ids.append(instr._id)In SASS, branches are instructions like BRA or BRX (indirect branch). The opcode check is simple, and the hard work is in def-use construction and taint propagation.
Handling Loops: Iterative Fixed-Point
Tasks 1-3 handle acyclic CFGs (no loops). Task 4 extends the analysis to loops, and this is where the dataflow framework shows its power.
In a loop, a register definition inside the loop body can reach a use that precedes it in program order (because the loop back-edge creates a cycle in the CFG). A non-iterative traversal would miss this.

The fix is the standard iterative fixed-point algorithm:
- Initialize all def-use information to empty sets
- Process all basic blocks (in some order; reverse post-order is efficient)
- For each basic block, recompute the def-use information considering all predecessors
- Repeat until no information changes
The “no changes” termination condition is the key insight: once the analysis has propagated all possible def-use relationships (including around all loops), additional iterations don’t add new information. For simple loops, this converges in a small number of passes. Deeply nested loops require more passes, but always terminate because the information only grows (it’s a monotone framework on a finite lattice).
Why This Matters
This analysis is not just a course project, it’s what real GPU compilers do.
NVIDIA’s PTX compiler and LLVM’s NVPTX backend both perform divergence analysis as part of the compilation pipeline. The purposes:
- Reconvergence annotation: Mark each divergent branch with its immediate post-dominator so the hardware knows where to reconverge warps
- Predication decisions: If a branch body is small enough and the branch is divergent, convert it to predicated instructions to avoid the divergence cost entirely
- Warp specialization: An advanced optimization where the compiler generates specialized code for “all threads take this branch” vs. “threads are split,” avoiding masking overhead in the common case
- Developer feedback: Modern profilers can report detected divergent branches, and that detection logic is dataflow analysis
A broader lesson is that classical compiler techniques developed for vectorizing sequential loops in the 1980s, such as reaching definitions, def-use chains, and iterative fixed-point analysis, are directly applicable to GPU branch divergence detection. The hardware model changed dramatically, but the analysis framework did not.
This is also where the compiler-hardware handshake is most visible. The compiler can annotate likely divergence structure (for example, branch and reconvergence metadata based on post-dominators) and decide when small branches should be predicated instead of branched. The hardware then executes that guidance through active masks, reconvergence machinery, and issue-time dependency checks.
Conclusion
Project 5 is the most “pure computer science” project in the course: no GPU hardware, no CUDA, just Python, control flow graphs, and dataflow analysis. But it closes a loop that the hardware-focused projects left open.
After the earlier projects you know what branch divergence costs: serialized execution, idle arithmetic units, wasted throughput. Project 5 shows you how compilers see it coming: by tracking thread ID taint through the def-use graph until it reaches a branch. The hardware’s divergence handling mechanisms (SIMT stacks, active masks, reconvergence) are responses to a problem that the compiler already knows about statically.
The iterative fixed-point algorithm is one of those ideas that keeps appearing in different forms throughout computer science. Here it shows up as the mechanism that makes loop analysis tractable: rather than reasoning about all possible execution paths (exponential), you propagate information monotonically around the CFG until it stabilizes (polynomial). The analysis doesn’t need to enumerate every possible loop iteration; it just needs to propagate information far enough that every def-use relationship is captured.
Additional Resources
- LLVM Divergence Analysis (2018) - the current LLVM implementation of GPU divergence analysis
- Late Divergence Analysis for LLVM (2021) - recent improvements to LLVM’s approach, referenced in the project README
- Dynamic Warp Formation and Scheduling (Fung et al., MICRO 2007) - hardware-side perspective on handling divergence dynamically

Compilers: Principles, Techniques, and Tools
Alfred V. Aho, Monica S. Lam, Ravi Sethi, Jeffrey D. Ullman
The “Dragon Book”: chapters 8 and 9 cover dataflow analysis, reaching definitions, def-use chains, and the iterative fixed-point algorithm in depth. The theory underlying Project 5 is classical compiler material, and this is the canonical reference for it.
In accordance with Georgia Tech’s academic integrity policy and the license for course materials, the source code for this project is kept in a private repository. This post follows Dean Joyner’s advice on sharing projects with a focus not on any particular solution but on an abstract overview of the problem and the underlying concepts involved.
I would be happy to discuss implementation details, algorithm design choices, or test case results in an interview. Please feel free to reach out to request private access to the repository.